


Boosting AI-assisted processing of satellite imagery for crop classification
Andrea Miola and Sebastiano Fabio Schifano
University of Ferrara (Ferrara, Italy)
Introduction
Modern satellite networks generate vast amounts of data, yet turning this into actionable agricultural insight remains a major challenge. In this contribution, we address this gap by combining Artificial Intelligence (AI) and High-Performance Computing (HPC). We focus on crop classification from satellite imagery to automate the generation of accurate and scalable crop maps. By integrating these technologies, raw remote sensing data can be transformed into effective decision-support tools for agriculture, leveraging high-throughput and energy-efficient processing relevant in green computing.
Why crop-classification matters
Tracking crop location, growth, and seasonal health is fundamental for sustainable agriculture, providing reliable baselines for environmental research, enabling smart resources management, while strengthening food security and climate resilience.
Our methodology builds classification maps using multi-temporal, multi-spectral satellite imagery collected over several months, covering either a full agronomic year or a specific growing season (e.g., January to July), when the most significant field changes occur.
Unlike single-date snapshots, multi-temporal stacks capture seasonal growth dynamics of fields. Neural Networks (NN) recognise these dynamics as unique phenological crop signatures by combining spatial and temporal patterns. Ultimately, this process produces consistent, large-scale classification maps that support agricultural monitoring and decision-making.
Powering AI with GPUs
Training complex NN models on massive datasets requires millions of parallel computations, a task perfectly suited for Graphics Processor Units (GPU). Originally designed for the graphics and gaming markets, the massively parallel architecture of GPUs has become essential for AI, especially Deep Learning (DL), a class of NN with several layers and nodes suitable to process thousands of features. Unlike traditional CPUs, GPUs integrate thousands of smaller, specialised cores able to execute thousands of operations in parallel, significantly accelerating model training and enabling high-speed inference at scale.
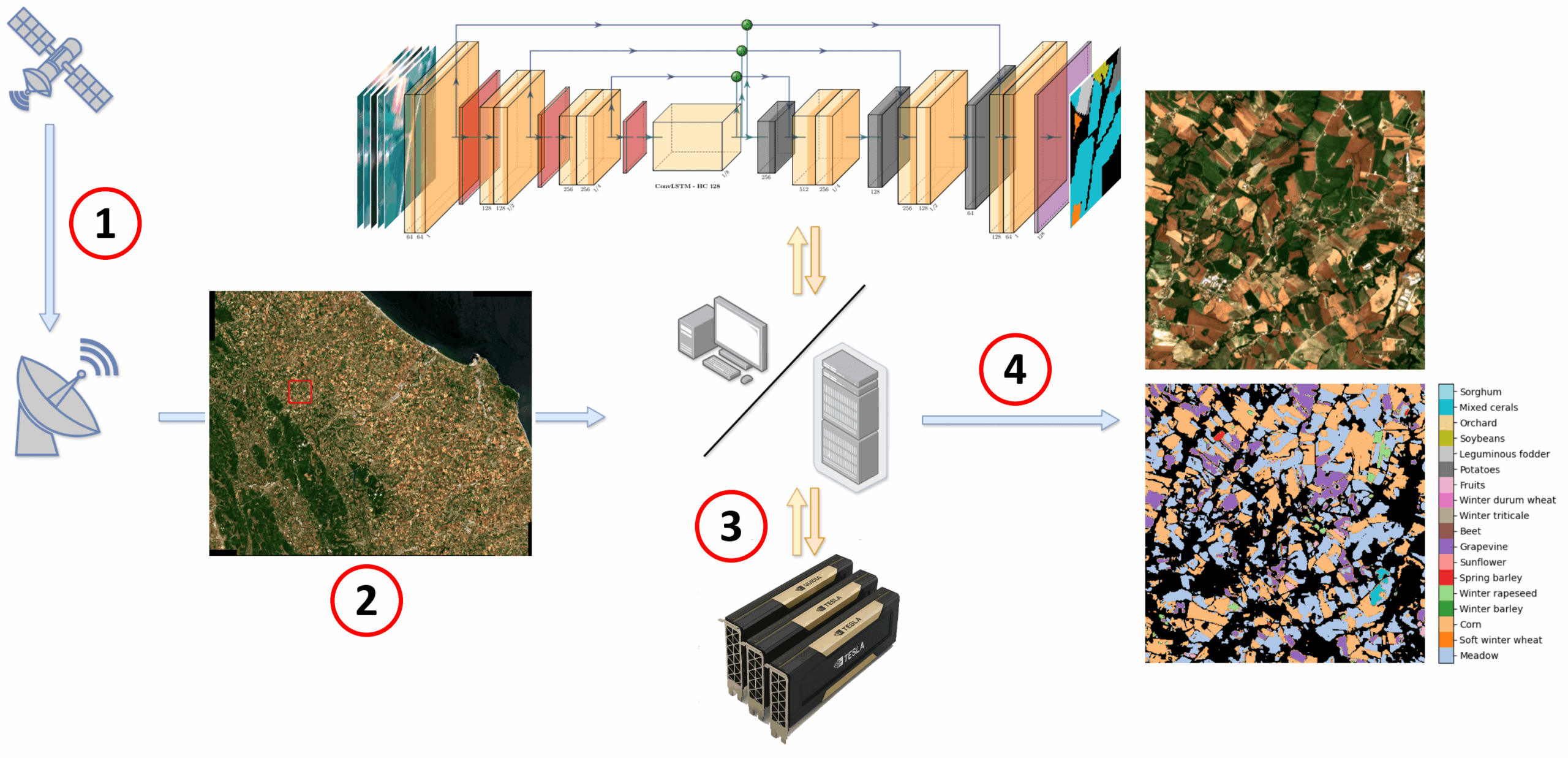
The Figure above illustrates the four key steps of the workflow of our computing pipeline:
- Acquisition: collection of raw data from satellite network imagery,
- Selection: definition of the geographic area of interest,
- Processing: execution of the AI model on the GPU-powered computing facility,
- Output: generation of colour-coded crop classification maps.
AgrUNet: a specialised NN for crop classification
Within the EU-HORIZON MESEO project, we developed AgrUNet, a Convolutional NN (CNN) design to process raw satellite data into reliable crop maps. The AgrUNet model is based on the U-Net architecture, a U-shaped NN originally conceived for medical imaging and widely adopted for image segmentation tasks. The architecture consists of two primary branches:
- a downward encoder to capture spatial features;
- an upward decoder to reconstruct the segmentation maps.
Following the original U-Net design, AgrUNet integrates multiple 3D convolution operators within both branches. To capture temporal dynamics, we enhanced the architecture by integrating a Long Short-Term Memory (LSTM) layer at the bottleneck.
To ensure efficient, green, and high-performance computing, AgrUNet leverages four key hardware-software strategies:
- GPU processing: a strategy to offload computation on accelerator devices able to provide high FLOPs (floating-point operations) per Watt, enabling efficient large-scale green computing;
- Automatic Mixed numerical precision (AMP): a computational strategy commonly used in HPC and AI to make calculations faster and more memory-efficient by using different levels of numerical precision for different parts of the application, improving speed and reducing memory usage;
- Multi-GPU processing: a methodology to distribute both training and inference workloads across several GPUs, greatly reducing the time to process large amounts of data;
- Deep supervision implementation: a technique that uses extra feedback points called auxiliary loss functions added to the middle layers of the model instead of only at the final output, making training of complex NN more robust, precise, and efficient. It improves training stability and model accuracy.
AgrUNet is implemented in Python and leverages PyTorch Lightning for GPU acceleration, a deep learning framework that supports distributed training and inference across multi-accelerator platforms.
Within the MESEO framework, AgrUNet is deployed as a Docker-based microservice running in a Linux environment. When a user selects an area of interest, the GMV Prodigi® [1] orchestrator automatically triggers the service to generate colour-coded crop classification maps.
Results
We validated AgrUNet on two open-source datasets based on Sentinel-2 (S2) imagery:
- OrthoPASTIS (based on [2]);
- Munich [3],
achieving a segmentation Dice scores of 0.86 and 0.93, respectively.
Computing performance tests were conducted on a GPU cluster at the University of Ferrara, operated in collaboration with INFN. The system configuration includes two Intel Gold 6242 CPUs operated at 2.8 GHz, 394 GB of RAM, and four NVIDIA V100-SXM2 (with 32GB memory each) GPUs interconnected via high-speed NVLink technology. This infrastructure was utilized for all stages of development, including model training, hyperparameter tuning, testing, and benchmarking.
| Dataset | Config | Training (speedup) | Inference (speedup) |
| OrthoPASTIS | 1x V100 | 9 | 41 |
| 4x V100 | 35 (~3.9x) | 152 (~3.7x) | |
| Munich | 1x V100 | 64 | 265 |
| 4x V100 | 248 (~3.9x) | 1057 (~4.0x) |
The table above summarizes our performance results. Using a single V100 GPU with mixed-precision computation enabled, we reached peak training throughputs of 9 images per second for OrthoPASTIS and 64 for Munich. During inference, these rates increased to 41 and 265 images per second, respectively.
These results represent a significant leap over existing literature, improving baseline performance by approximately 7x. Furthermore, scaling to four V100 GPUs yielded a near-linear speedup of roughly 4x for both training and inference. In this multi-GPU configuration, training throughput peaked at 35 (OrthoPASTIS) and 248 (Munich) images per second, while inference reached 152 and 1057 images per second. Ultimately, these performance gains are critical, as they enable the processing of full-time-series S2 tiles (covering approximately 110×110 km²) in a substantially reduced timeframe.
Energy efficiency
| Watt | J / img | ||
| Inference | CPU – FP32 | 132 | 584 |
| GPU – FP32 | 235 | 18 | |
| GPU – AMP | 185 | 6 | |
| Training | CPU – FP32 | 132 | 1891 |
| GPU – FP32 | 258 | 86 | |
| GPU – AMP | 185 | 20 |
The table above evaluates the energy efficiency and performance of an NVIDIA V100 GPU against 2X Intel Xeon Gold 6242 for a total of 32-core CPUs. Benchmarks were conducted using the OrthoPASTIS dataset, consisting of a 2-epoch training phase and an inference run of 800 images (100 batches of 8). Testing compared standard 32-bit floating-point (FP32) arithmetic and AMP, where supported.
Looking at the inference, at a glance, the GPU may appear less environmentally friendly due to higher instantaneous power draw (235W for FP32 and 185W for AMP vs. the CPU’s 132W). However, in the field of Green Computing, the critical metric is not raw Wattage, but energy consumed per unit of work, measured here in Joules per image (J/img). While the GPU draws more power instantly, the superior throughput allows it to complete tasks much faster. By switching from the CPU to the GPU with AMP enabled, energy consumption drops from 584J to just 6J per image, a 99% reduction in total energy usage.
This efficiency translates directly into a dramatic reduction in carbon footprint. Based on the 2024–2025 IEA estimate [4] of 445 g CO2/kWh, an inference task of 1,000,000 images on the CPU would emit approximately 72 kg of CO2, equivalent to leaving a 100Watt bulb on for approximately 70 days 24/7. By contrast, performing the same task on the GPU with AMP reduces those emissions to just 740 grams, a nearly 100-fold improvement, corresponding to leaving the bulb on for just approximately 17 hours.
Similar trends are observed during the training phase, where the GPU outperforms the CPU’s energy efficiency by approximately two orders of magnitude.
Conclusion
Our results indicate that in sustainable AI, efficiency is driven by high throughput rather than simply low power consumption (Watts). By maximizing ‘work per watt,’ GPUs prove to be the most effective processors for reducing the carbon footprint of modern AI infrastructure, particularly when utilizing mixed-precision arithmetic. Relying on these features, this work shows how combining AI and HPC enables scalable, accurate, and energy-efficient crop classification from satellite imagery. In conclusion, AgrUNet contributes to the development of sustainable AI and digital agriculture solutions, aligning with the goals of the MESEO project.
[1] Prodigi® http://www.gmv.com/products/space/gmv-prodigi
[2] PASTIS https://github.com/VSainteuf/pastis-benchmark
[3] Munich https://github.com/TUM-LMF/MTLCC
[4] International Energy Agency (IEA) https://www.iea.org/reports/electricity-2025/emissions
- UNIFE
- April 8, 2026
- 12:57 pm